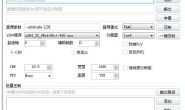
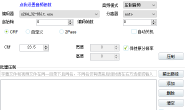
win10电脑虚拟内存设置多少合适
https://z197.com/blog/win10-virtual-memory-setting-suitable-32g-16g.html
虚拟内存和硬件内存有什么区别
https://z197.com/blog/virtual-memory-hardware-memory-difference.html
gpu显卡型号和cpu型号怎么看
https://z197.com/blog/differences-between-cpu-and-gpu.html
电脑cpu的插槽,内核,逻辑处理器概念详解
在使用小丸工具箱压缩视频时,编码器有很多选项。
其中的10bit和8bit有很多人不清楚是什么,有什么区别。
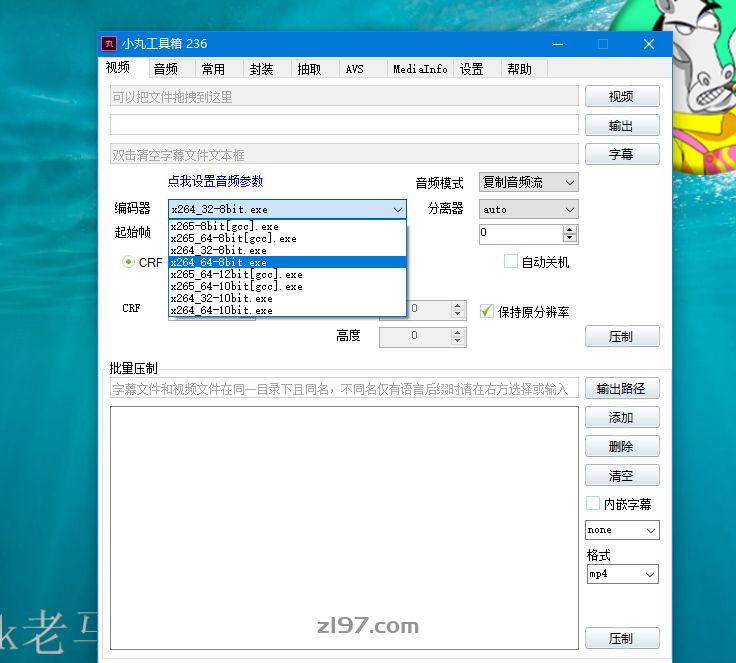
编码器10bit和8bit区别
我们知道为了获得更好的动态范围,除了常见的8bit yuv外,还有10bit,16bit这样的yuv数据。8bit的yuv数据还好理解,每一个像素8bit,在内存中自然也就是一个字节一个字节的存储咯,16bit的也类似,每一个像素对应两个字节,在内存中存起来也非常方便,那么10bit呢?
在不做任何调查的情况下,我们可以凭直觉猜想有两种存储方式:
1.每个像素依然占用16bit两个字节,但是其中6个bit是padding,补0
2.每个像素实打实地占用10bit,各个像素交织在一起,没法整齐地分布在字节中
第一种方式便于运算处理,但是有存储冗余。
第二种方式则没有冗余,但是计算起来就很麻烦了。
事实上,10bit是采用第一种方式存储在内存中的,也就是说,为了高动态范围,牺牲了一点压缩效率,但也获得了运算性能的加成,大概就是多媒体技术里无处不在的trade off了。
8bit像素数据是如何转换为10bit像素数据的呢
根据SMPTE 274M标准,就是乘上一个系数2^(n-8),这里的n就是位深,也就是10或者16,所以如果要把8bit yuv数据转成10bit,就是乘4,即左移两位。
下面验证一下:
使用如下命令将8bit yuv转为10bit
ffmpeg -s 240×120 -i test.yuv -pix_fmt yuv420p10be test10.yuv
这里的yuv420p10be即10bit yuv420p 大端 格式。各种像素格式可以用如下命令列出
ffmpeg -pix_fmts
原文件大小为1055KB,转出来的test10.yuv的大小正好是它的2倍,2110KB。验证了每像素16bit的说法。
再用UltraEdit看看每个像素的2进制数据
在test.yuv中的第一个Y的2进制数据如下
1001 0010
在test10.yuv中对应的样点的2进制数据如下
0000 0010 0100 1000
可以看到,在原来的基础上左移两位,后面补上两个0,这是实际的10bit数据,前面再补上6个0,是padding位
编码10bit视频时用10bit进行编码会比8bit编码获得更好的质量。
这个容易理解:使用8bit编码需要首先对原始信号进行缩放,编码后还需要缩放,缩放就会造成更多的失真。
换句话说,压缩会比直接缩放带来更小的失真。因此使用10bit编码器压缩10bit视频会节省带宽。
然而,实际上,即使是8bit视频,采用10bit进行编码依然会比8bit编码节省带宽。即10bit始终比8bit节省带宽,与原始像素的bitdepth无关。
具体原因接下来从以下五点进行解释:
什么是节省带宽
节省带宽意味着同样的视频质量,需要的bitrate更低,可以通过BD-rate来体现
什么是较好的视频质量
视频质量好即解码图像与原始图像之间的相似性高,误差小。
这一点值得注意,8bit中的1位误差与10bit中的3位误差具相同的相对误差。
可以想象,像素值为0-255时,像素值由1编为2,与像素值为0-1023时,像素值由1编为5,是不是感觉差不多的。相当于人眼的精度只能分辨1/256的变化(假设)。
更直接的方法可以用psnr的计算公式来证明:
8bit时, p s n r _ 8 b i t = 10 l o g 10 ( 255 ∗ 255 / m s e _ 8 b i t ) psnr\_8bit=10log10(255*255/mse\_8bit) psnr_8bit=10log10(255∗255/mse_8bit)
而10bit10, p s n r _ 10 b i t = 10 l o g 10 ( 1023 ∗ 1023 / m s e _ 10 b i t ) psnr\_10bit=10log10(1023*1023/mse\_10bit) psnr_10bit=10log10(1023∗1023/mse_10bit)
令, p s n r _ 8 b i t = p s n r _ 10 b i t psnr\_8bit=psnr\_10bit psnr_8bit=psnr_10bit
得, 16 ∗ m s e _ 8 b i t = m s e _ 10 b i t 16*mse\_8bit=mse\_10bit 16∗mse_8bit=mse_10bit
假设只有一个像素,原始像素值为 p _ s r c p\_src p_src,重建像素值为 p _ d e c p\_dec p_dec
则有4 * (p_dec_8bit – p_src) = p_dec_10bit – p_src
所以懂了吧,10bit的误差可以是8bit的4倍,但是可以获得相同的PSNR
编码器如何编码10bit视频
上面说过,因为失真是相对的,所以10bit可以用4倍于8bit的量化步长而获得同样的相对失真,即PSNR。
而由于10bit用的量化步长是8bit的4倍,他们最终的量化等级数就都是一样的,也就是最终的比特数都是一样的。
比如8bit的量化步长如果是8的话,那0-255会被量化成32个等级,而10bit的量化步长就可以用32,最终也是32个量化等级。
相当于量化系数都是0-31,再熵编码是不是比特数也一样了呢。
照这样说,那10bit的编码结果应该和8bit完全一样呀,为什么会更好呢,我们接着往下说.
为什么10bit编码器要优于8bit编码器
当编码器使用10bit编码时,相比8bit有更少的阶段误差,尤其是运动补偿阶段,因此会增加压缩效率。
总的来说就是会在某些地方比8bit更好,所以最终才会节省带宽。
压缩过程中的失真是如何产生的
视频压缩过程中,主要产生失真的过程是量化。
量化可以简单理解为变换系数除以量化步长。
量化后的值再经过反量化得到的变换系数就与量化前的系数产生了误差。
因为量化是多对一的过程,多个变换系数会被量化成一个值,而反量化是一对一的过程,因此没办法完全恢复,所以就有了失真。
编码器如何编码10bit视频上面说过,因为失真是相对的,所以 r _ 8 b i t = p s n r _ 10 b i t psnr\_8bit=psnr\_10bit psnr_8bit=psnr_10bit
得, 16 ∗ m s e _ 8 b i t = m s e _ 10 b i t 16*mse\_8bit=mse\_10bit 16∗mse_8bit=mse_10bit
假设只有一个像素,原始像素值为 p _ s r c p\_src p_src,重建像素值为 p _ d e c p\_dec p_dec
则有4 * (p_dec_8bit – p_src) = p_dec_10bit – p_src
所以懂了吧,10bit的误差可以是8bit的4倍,但是可以获得相同的PSNR